Checkpoint - OpenDalleV1.1 an Impressive Update
OpenDalleV1.1 is here with updates and bold claims. Will it measure up?


I've been hearing a lot about OpenDalle and how people say it's "better than SDXL." So, I decided to do a comparison myself. For months, I've been looking at different models and versions, including the standard and turbo ones. Here's what I found out about OpenDalleV1.1.
OpenDalleV1.1 is a basic model that uses the same setup as Stable Diffusion XL Pipeline. So, if it's built on the same framework as SDXL, how is it any better? Well, let's take a closer look and find out what really makes them different!
Prompt Accuracy
The heart of OpenDalle's success is its unwavering commitment to prompt loyalty. Version 1.1 has been designed to adhere closely to your input, transforming your words into visuals that accurately reflect your intentions. This means that the images you receive are not just close approximations but detailed realizations of your vision. The technology has been fine-tuned to understand and interpret your prompts with a high degree of fidelity, ensuring that the end result is as close to your mental image as possible. So, let's put that statement to the test.
As someone who has extensively used and tested DALL-E3, I can say that this model isn't as good at following prompts. It's just not on the same level... at least not yet. Like all models, it has trouble remembering longer prompts, and the more words you add, the less accurate the results seem to be.
For example, I ran this prompt in DALL-E3.
Photo depicting an NVIDIA GPU as the centerpiece on a spacious desk. The room's atmosphere is enhanced by glowing RGB lights that transition between different colors. The GPU's surface showcases every detail, from connectors to branding. In the background, there's a monitor displaying a wallpaper with vibrant colors.
On the very first try I got this image.
I ran the same prompt using OpenDalleV1.1 and got the following result.

It totally missed the main point of the photo, which was the Nvidia GPU, and just gave me a picture of a desk with a monitor. I've seen this kind of thing happen over and over, not just with this model. It looks like it's a widespread problem with all SDXL based models, but I guess it'll get fixed eventually as we figure out ways to improve AI functionality.
To OpenDalle's defense, using longer prompts in Stable Diffusion for any model often times ends up with results that are not accurate. So I did run another test with a much shorter prompt and it did seem to do pretty well! But I had to try a longer one just to see.
Realistic Portraits
I was really amazed to see how the model could create such realistic portraits of people. I made this image using just the model, without any extra tools or styles. I like to see the pure look of the portrait, and that's how I always do my model/checkpoint studies. This particular gen used a guidance scale of 2 and all of the images you see below were cherry picky from 3 batches of 6 images.

I noticed that whenever I added "black and blue gradient background" to my request, the eyes would almost always turn out blue as well, which was pretty annoying. It's like if the color blue is in the portrait prompt, it chooses blue for the eyes over any other color, even if you specifically ask for a different eye color. I've seen this happen with other models too.


Left guidance scale 7, right guidance scale 2
Another important observation is that the quality of landscape images seems to significantly decline. The drop is quite dramatic, with details often appearing muddled and colors lacking the depth and richness you'd expect. This isn't just an occasional slip, it's a recurring problem that stands out, especially when compared to the results from other types of images. It makes you wonder about the model's limitations and how it interprets different subjects. Here's a quick example to illustrate what I'm talking about. This consistent issue points to a need for improvement in how the model handles more complex and varied scenes.

Hands and Fingers
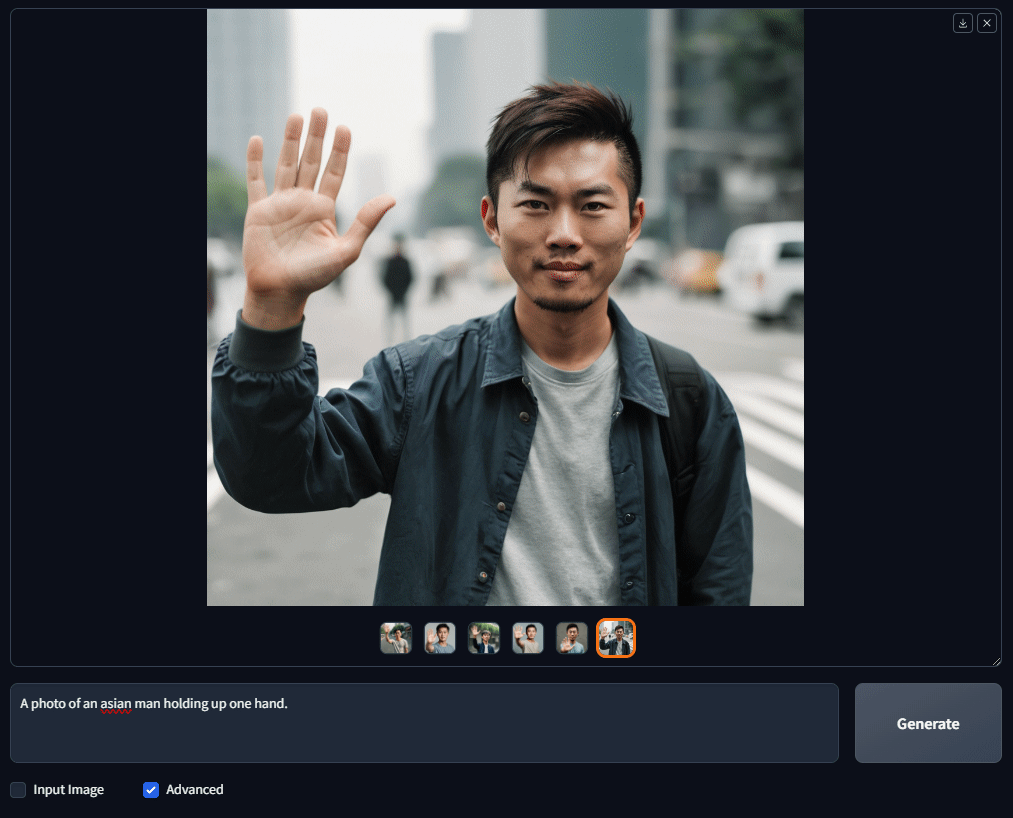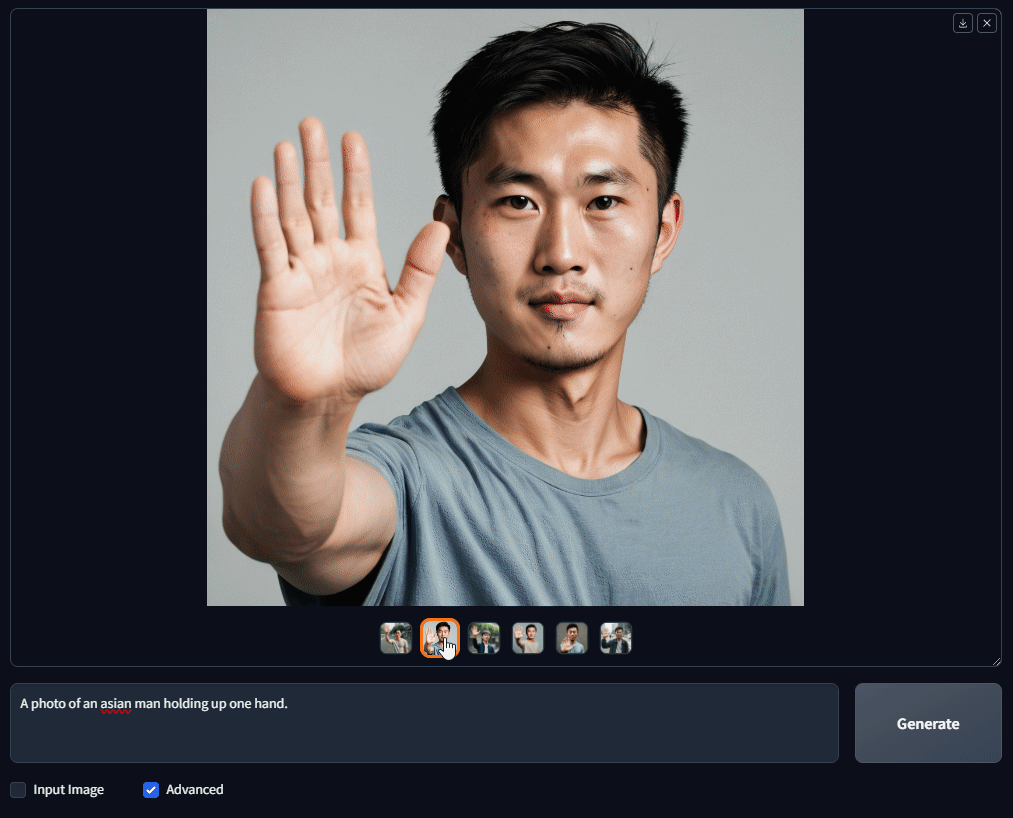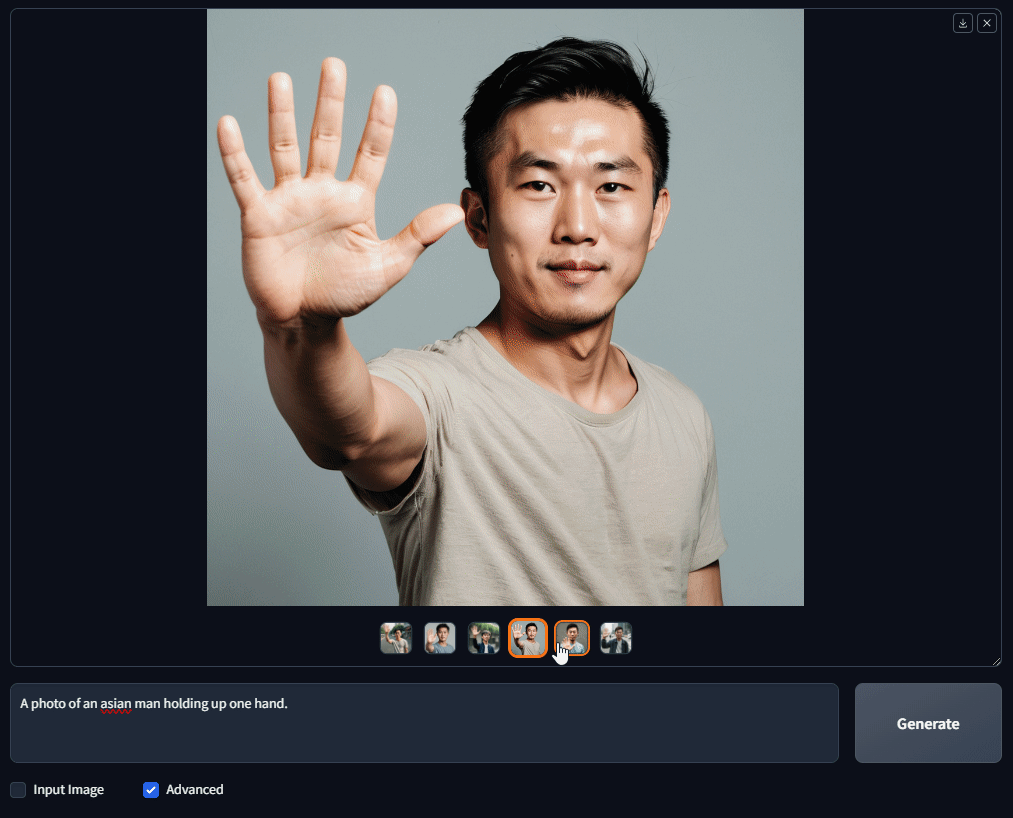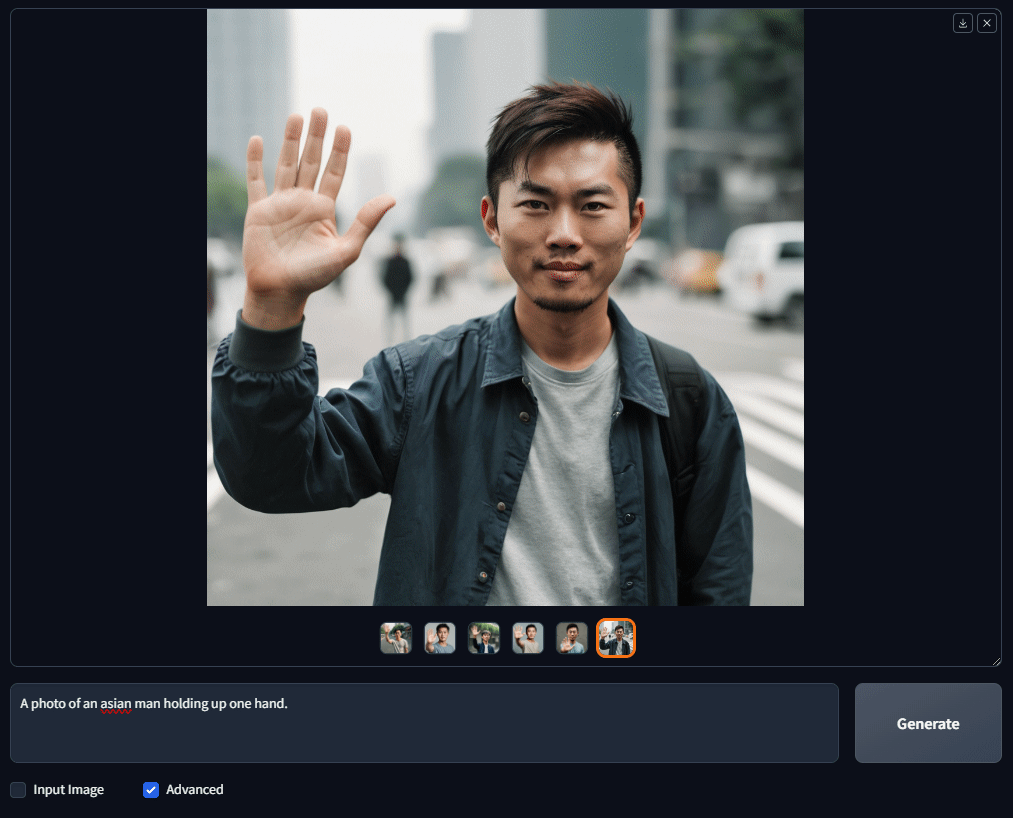
I decided to test how accurately the model could create hands and fingers. So, I used a very simple prompt: "A photo of an Asian man holding up one hand." I generated a batch of 6 images, and guess what? Every single image came out with all 5 fingers!

Although the hands aren't perfect, the results are much better than what I've seen with other models. For sure, OpenDalleV1.1 gets a 9 out of 10 for its depiction of hands and fingers!
In the grand scheme of things, OpenDalle v1.1 has positioned itself as a formidable player in the field, confidently standing out with its unique offerings. While it acknowledges the superiority of DALLE-3, OpenDalle doesn't shy away from making its own mark. It's like the innovative middle child of the family, not just following in the footsteps of its predecessors but also adding its own twist to the mix. With a balance of advanced capabilities and a fresh approach, OpenDalle v1.1 is carving out its niche, offering users a smart, stylish, and reliable option for bringing their visual ideas to life.
I definitely see the potential in the model, it's there! But it's becoming increasingly hard to go back to using models that take 60 steps to create images when there are so many turbo models available that only need 6-10 steps. Plus, these other models also deliver fantastic results. So, what's the best choice?
And hey, don't just take my word for it! Give OpenDalleV1.1 a try for yourself and put it to the test. Does it measure up to it's claims and hype? You be the judge!